了解 IBM WebSphere Application Server 健康管理以及如何创建健康策略。
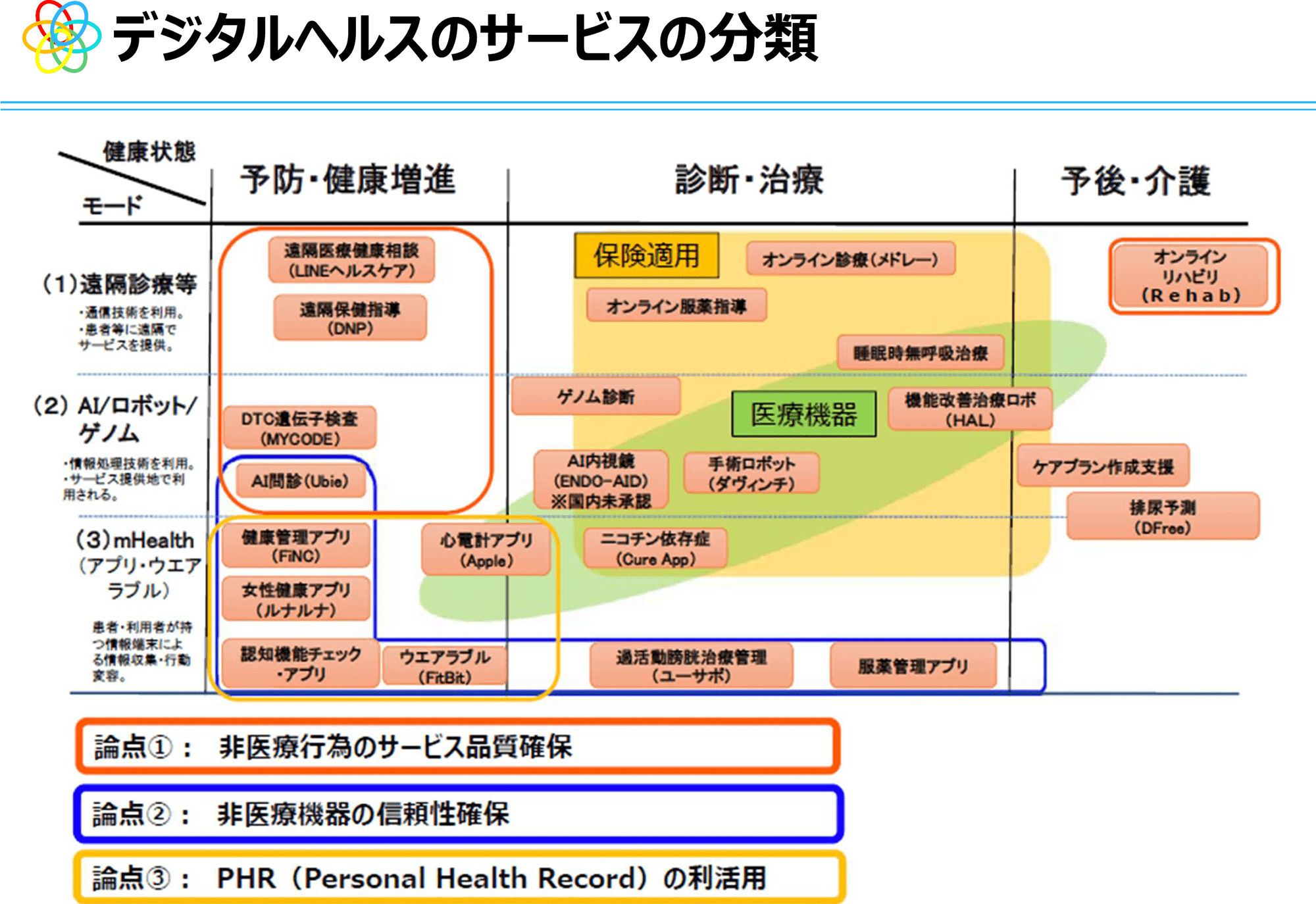
什么是医疗保健?
健康管理是 WebSphere Virtual Enterprise 环境的一部分,并集成到 WebSphere Application Server 8.5 中。
WebSphere 8.5 与利用健康策略的运营策略集成。
健康管理是一种策略驱动的方法,用于监视 WebSphere 企业应用程序服务器的使用情况,以便您可以在发生中断之前解决问题区域。
健康管理有两个组成部分:
- 健康控制器
- 卫生政策
什么是反应模式?
健康策略包含您想要在环境中监控的健康状态。当未满足定义的要求时做出反应。
有两种反应模式。
- 自动模式:当检测到违反健康策略时,系统将采取行动。
例如,如果您配置了内存使用率监控,并希望在消息使用率达到 85% 时重新启动 JVM,则系统会在 JVM 堆大小达到 85% 时重新启动目标 JVM。
- 监控模式:当检测到健康策略违规时,系统创建运行时任务。这需要 WebSphere 管理员手动干预来批准或拒绝运行时任务的操作。
什么是健康状况?
健康状况是监视您的环境的对象或指标。
WebSphere 8.5 中提供了八种预定义的健康状态。还有一个选项可以创建自定义健康状态。
- 基于经过时间的条件 – 此条件监视定义的 JVM,并在达到设定的经过时间阈值时采取操作。
原来的:
如果JVM已经运行了15天,您可以设置此条件来重新启动JVM。在这种情况下可接受的值为天或小时,如下所示。

- 请求超时条件过多– 当请求超时百分比超过定义的值时,此条件将发生操作。可接受的值以百分比表示,如下所示。
- 超出响应时间条件 – 监视请求完成所需的时间,并在该时间超出定义的阈值时采取操作。
原来的:
如果请求响应时间为 1 分钟,您可以配置此条件以进行线程转储。可接受的值以毫秒、秒和分钟为单位,如下所示。

- 内存状况:内存使用过多– 监视 JVM 内存使用情况,并在超出阈值时采取措施。
原来的:
您可以设置此条件以在内存使用量超过阈值时进行 JVM 堆转储并重新启动 JVM。如下所示,JVM 堆大小容差是百分比,感兴趣的时间段是秒和分钟。
- 内存状态:内存泄漏– 搜索 JVM 上的内存泄漏并采取措施。
这导致了三个检测级别。
- 快速(误报)
- 标准(一些误报)
- 慢(误报少)
- 风暴耗尽条件 – 观察平均响应时间的显着下降并采取措施,例如生成线程转储或重新启动 JVM。

现在您有两个检测级别。
- 标准(一些误报)
- 慢(误报少)
- 工作负载条件 – 此条件检测 JVM 何时处理配置数量的请求。
原来的:
您可以将 JVM 配置为在 20000000 个请求后重新启动。
- 垃圾收集百分比条件 – 此条件监视在定义的时间段内垃圾收集所花费的时间百分比,并在超过阈值时采取操作。允许的值为如下所示的百分比和采样周期。
什么是健康行动?
健康操作是超出配置的阈值时发生的健康策略操作。
WebSphere 8.5 中提供了七个预定义的运行状况操作。

- 重启服务器——重启JVM
- 获取线程转储 – 获取 JVM 的线程转储。
- 获取 JVM 堆转储 – 获取 JVM 堆转储。
- 生成 SNMP 陷阱 – 生成 SNMP 陷阱以进行故障排除
- 将服务器置于维护模式 – 停止新的客户端请求并仅处理活动会话
- 将服务器置于维护模式并中断关联性。停止新的和现有的操作会话。
- 退出维护模式 – 准备接受新请求
还有一个选项可以创建自定义健康操作。
如何制定健康政策?
只需四个简单步骤即可制定健康政策。
- 定义健康策略的一般属性。在此处指定您的策略的名称并选择健康状态。
- 定义健康策略的健康状态属性。您可以在此处提供所选健康状态的阈值,并配置违反健康状态时应采取的操作。
- 指定要监视的成员 – 选择 JVM、集群、动态集群、按需路由器或单元作为运行状况策略目标
- 验证健康策略创建 – 验证健康策略配置并确认创建。
让我们制定如下一项卫生政策。
- 登录到 WebSphere 8.5 ND DMGR 控制台。
- 点击“运营政策>>健康政策”。
- 点击“新建”
- 指定名称 – Test_Policy
- 选择 Health 作为工作负载条件(您可以立即测试此条件)
- 单击下一步
- 输入“请求总数”为“1000”以进行测试。
- 选择反应模式为自动
- 添加操作重新启动服务器并进行线程转储

- 单击下一步
- 选择过滤器作为服务器/节点。
- 添加 server1 作为目标成员
- 单击下一步
- 检查配置并单击完成
现在让我们访问并测试在目标 JVM (server1) 上运行的应用程序。
一旦 JVM 处理了 1000 个请求,您将需要进行线程转储并重新启动它。使用 JMeter 加载可以让您快速测试。
什么是健康控制器?
健康控制器控制健康策略并监控系统。要监控您的策略,您必须在健康控制器上启用健康监控。
运行状况控制器本身具有可配置的属性,例如运行频率以及在某些情况下重新启动服务器的频率。
这允许您限制服务器在高峰时段的重新启动。
卫生政策目标是什么?
健康策略或操作的目标可以是 JVM、集群、动态集群、按需路由器或单元。
我希望这可以帮助您更好地理解。如果您有兴趣学习 DevOps,请查看此基础课程。




![2021 年如何设置 Raspberry Pi Web 服务器 [指南]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)

