
Apache Hive は、大規模な分析を可能にする分散型フォールトトレラント データ ウェアハウス システムです。
データ ウェアハウスは、データ分析とレポート作成を目的として、さまざまなソースから得られた大量の履歴データを保存するデータ管理システムです。これにより、ビジネス インテリジェンスがサポートされ、より多くの情報に基づいた意思決定が可能になります。
Apache Hive で使用されるデータは、分散データ ストレージと処理のためのオープンソース データ ストレージ フレームワークである Apache Hadoop に保存されます。 Apache Hive は Apache Hadoop 上に構築されているため、Apache Hadoop からデータを保存および抽出します。ただし、Apache HBase などの他のデータ ストレージ システムも使用できます。
Apache Hive の最も優れた点は、ユーザーが SQL に似た Hive Query Language (HQL) を使用して大規模なデータセットの読み取り、書き込み、管理、およびデータのクエリと分析を実行できることです。
Apache Hive の仕組み
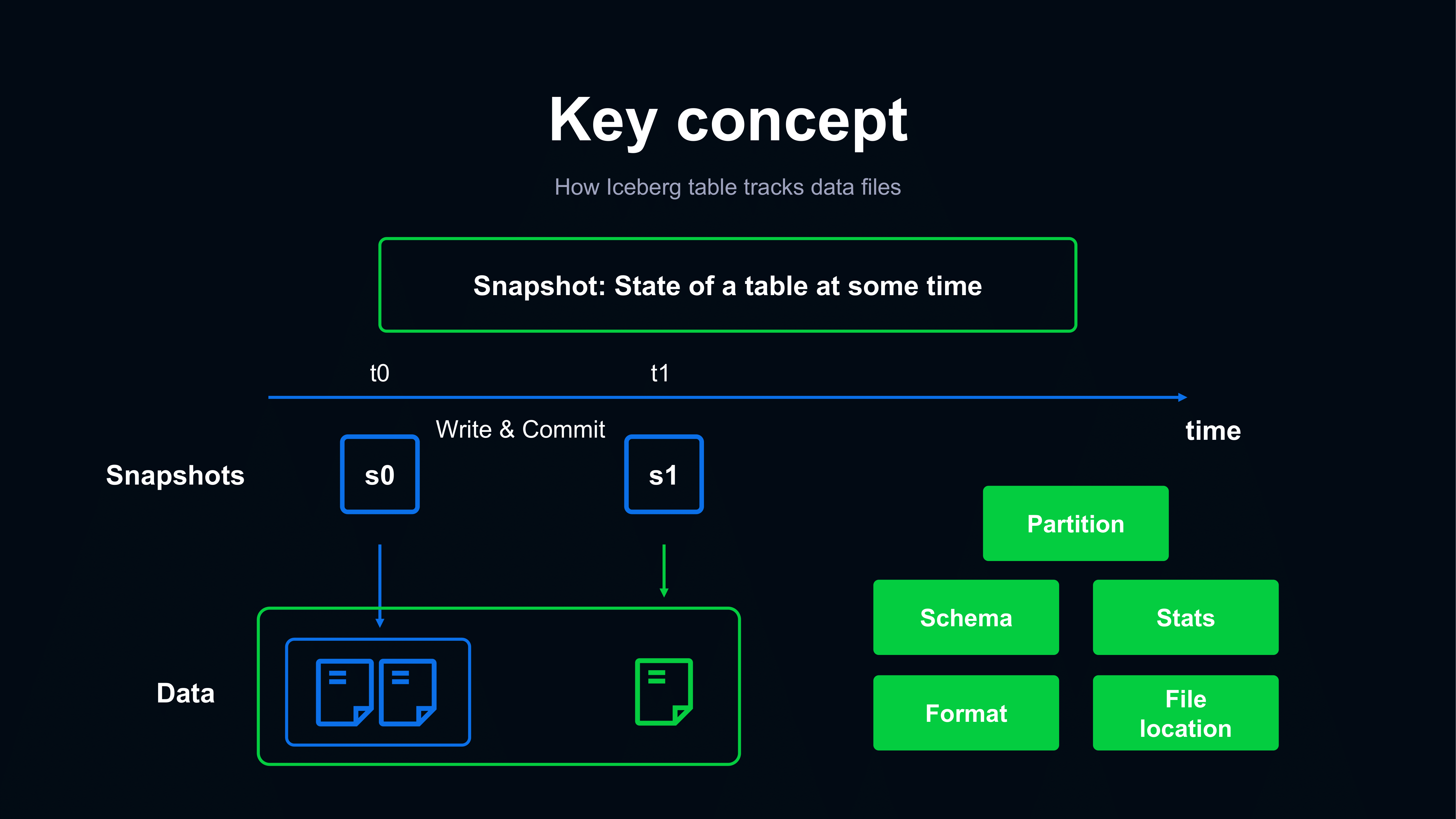
Apache Hive は、 Hadoop 分散ファイル システム (HDFS) に保存されている大量のデータをクエリおよび管理するための、高レベルの SQL に似たインターフェイスを提供します。ユーザーが Apache Hive でクエリを実行すると、そのクエリは Hadoop クラスタによって実行される一連の MapReduce ジョブに変換されます。
MapReduce は、分散されたコンピューター クラスター間で大量のデータを並列処理するためのモデルです。 MapReduce ジョブが完了すると、その結果が処理されて結合され、単一の最終結果が生成されます。最終結果は、Hive テーブルに保存することも、HDFS にエクスポートしてさらに処理または分析することもできます。
Hive のクエリは、パーティションを使用してテーブル情報に基づいて Hive テーブルをさまざまな部分に分割することで、より高速に実行できます。これらのパーティションをさらに分割して、大規模なデータ セットのクエリを非常に高速に実行できるようにすることができます。このプロセスはバケット化として知られています。
Apache Hive は、ビッグ データを扱う組織にとって必需品です。これは、大規模なデータセットを簡単に管理し、データを非常に高速に処理し、データに対して複雑なデータ分析を簡単に実行できるためです。これにより、利用可能なデータから包括的かつ詳細なレポートが作成され、より適切な意思決定が可能になります。
Apache Hive を使用する利点
Apache Hive を使用する利点には次のようなものがあります。
使いやすい
SQL と同様に HQL を使用したデータのクエリを許可することで、プログラマと非プログラマの両方が Apache Hive を使用できるようになります。したがって、新しい言語や構文を学習することなく、大規模なデータ セットに対してデータ分析を行うことができます。これは、組織による Apache Hive の採用と使用に大きく貢献しています。
速い
Apache Hive を使用すると、バッチ処理を通じて大規模なデータセットの非常に高速なデータ分析が可能になります。バッチ処理では、大規模なデータセットがグループに収集され、処理されます。結果は後で結合されて、最終結果が生成されます。 Apache Hive はバッチ処理を通じて、高速な処理とデータ分析を可能にします。
信頼性のある
Hive は、データ ストレージに Hadoop 分散ファイル システム (HDFS) を使用します。連携することで、分析中にデータを複製できます。これにより、コンピュータシステムが故障した場合でもデータが失われることのないフォールトトレラントな環境が構築されます。
これにより、Apache Hive は非常に信頼性が高く、耐障害性が高く、他のデータ ウェアハウス システムの中でも際立っています。
スケーラブル
Apache Hive は、増加するデータセットを簡単に拡張して処理できるように設計されています。これにより、ニーズに応じて拡張できるデータ ウェアハウス ソリューションがユーザーに提供されます。
費用対効果の高い
他のデータ ウェアハウス ソリューションと比較して、オープン ソースである Apache Hive は比較的運用コストが安いため、収益性を高めるための運用コストを最小限に抑えることに熱心な組織にとって最適なオプションです。
Apache Hive は、ユーザーのニーズに応じて拡張するだけでなく、高速でコスト効率が高く、使いやすいデータ ウェアハウス ソリューションを提供する、堅牢で信頼性の高いデータ ウェアハウス ソリューションです。
Apache Hive の機能
Apache ハイブの主な機能は次のとおりです。
#1. ハイブサーバー2(HS2)
認証とマルチクライアント同時実行性をサポートし、Java Database Connectivity (JDBC) や Open Database Connectivity (ODBC) などのオープン API クライアントのサポートを強化するように設計されています。
#2. Hiveメタストアサーバー(HMS)
HMS は、リレーショナル データベースの Hive テーブルおよびパーティションのメタデータの中央ストアとして機能します。 HMS に保存されたメタデータは、メタストア サービス API を使用してクライアントが利用できるようになります。
#3. ハイブACID
Hive は、実行されるすべてのトランザクションが ACID に準拠していることを保証します。 ACID は、データベース トランザクションの 4 つの望ましい特性を表します。これには、原子性、一貫性、分離性、耐久性が含まれます。
#4. Hive データの圧縮
データ圧縮は、データの品質と完全性を損なうことなく、保存および送信されるデータのサイズを削減するプロセスです。これは、圧縮されるデータの品質と整合性を損なうことなく、冗長性や無関係なデータを削除するか、特別なエンコードを使用することによって行われます。 Hive は、すぐに使えるデータ圧縮のサポートを提供します。
#5. ハイブのレプリケーション
Hive には、バックアップの作成とデータ回復を目的として、Hive メタデータのレプリケーションとクラスター間のデータ変更をサポートするフレームワークがあります。
#6. セキュリティと可観測性
Hive は、データ セキュリティの監視と管理を可能にするフレームワークである Apache Ranger や、企業がコンプライアンス要件を満たすことを可能にする Apache Atlas と統合できます。 Hive は、ネットワーク内の通信を保護するネットワーク プロトコルである Kerberos 認証もサポートしています。この 3 つを組み合わせることで、Hive が安全かつ監視可能になります。
#7。 ハイブ LLAP
Hive には Low Latency Analytical Processing (LLAP) があり、データ キャッシュの最適化と永続的なクエリ インフラストラクチャの使用により、Hive が非常に高速になります。
#8. コストベースの最適化
Hive は、 Apache Calcite によるコストベースのクエリ オプティマイザーとクエリ実行フレーマーを使用して SQL クエリを最適化します。 Apache Calcite は、データベースとデータ管理システムの構築に使用されます。
上記の機能により、Apache Hive は優れたデータ ウェアハウス システムになります
Apache Hive の使用例
Apache Hive は、ユーザーが大量のデータを簡単に処理および分析できるようにする、多用途のデータ ウェアハウスおよびデータ分析ソリューションです。 Apache Hive の使用例には次のようなものがあります。
データ分析
Apache Hive は、SQL のようなステートメントを使用した大規模なデータ セットの分析をサポートします。これにより、組織はデータ内のパターンを特定し、抽出されたデータから有意義な結論を導き出すことができます。デザイン作成に役立ちます。データ分析とクエリに Apache Hive を使用する企業の例には、AirBnB、FINRA、Vanguard などがあります。
バッチ処理
これには、Apache Hive を使用して、グループ内の分散データ処理を通じて非常に大規模なデータセットを処理することが含まれます。これには、大規模なデータセットを高速に処理できるという利点があります。この目的で Apache Hive を使用する企業の例としては、保険および資産管理会社である Guardian があります。
データウェアハウジング
これには、Apache ハイブを使用して非常に大規模なデータセットを保存および管理することが含まれます。これに加えて、保存されたデータを分析し、そこからレポートを生成することもできます。データ ウェアハウス ソリューションとして Apache Hive を使用している企業には、JPMorgan Chase や Target などがあります。
マーケティングと顧客分析
組織は、Apache Hive を使用して顧客データを分析し、顧客のセグメント化を実行して顧客をより深く理解し、顧客の理解に合わせてマーケティング活動を調整することができます。顧客データを扱うすべての企業がApache Hiveを利用できるアプリケーションです。
ETL(抽出、変換、ロード)処理
データ ウェアハウスで大量のデータを扱う場合、データをデータ ウェアハウス システムにロードして保存する前に、データのクリーニング、抽出、変換などの操作を実行する必要があります。
これにより、データの処理と分析が迅速かつ簡単になり、エラーがなくなります。 Apache Hive は、データがデータ ウェアハウスにロードされる前に、これらすべての操作を実行できます。
上記は、Apache Hive の主な使用例を構成します。
学習リソース
Apache ハイブは、大規模なデータセットのデータ ウェアハウジングとデータ分析に非常に便利なツールです。大規模なデータセットを扱う組織や個人は、Apache ハイブを使用することで恩恵を受けることができます。 Apache Hive とその使用方法の詳細については、次のリソースを参照してください。
#1. Hive To ADVANCE Hive (リアルタイム使用)
Hive to Advance Hive は、データ分析や他のユーザーのトレーニングのために Apache テクノロジーを使用して 10 年以上の経験を持つシニア ビッグデータ コンサルタントである J Garg によって作成された Udemy のベストセラー コースです。
これは、Apache Hive の基本から高度な概念まで学習者を導くユニークなコースで、Apache Hive の面接で使用されるユースケースに関するセクションも含まれています。また、学習者が学習中に練習できるデータセットと Apache Hive クエリも提供します。
取り上げられる Apache Hive の概念には、Hive の高度な機能、Hive の圧縮技術、Hive の構成設定、Hive での複数のテーブルの操作、Hive での非構造化データのロードなどがあります。
このコースの強みは、実際のプロジェクトで使用される高度な Hive の概念を詳しくカバーしていることにあります。
#2. データ エンジニアのための Apache Hive
これは実践的なプロジェクトベースのUdemyコースで、実際のプロジェクトに取り組むことで、初心者レベルから上級レベルまでApache Hiveを操作する方法を学習者に教えます。
このコースは Apache Hive の概要から始まり、Apache Hive がデータ エンジニアにとって必要なツールである理由を説明します。次に、Hive アーキテクチャ、そのインストール、および必要な Apache Hive 構成について説明します。基礎を築いた後、コースはハイブのクエリ フロー、ハイブの機能、制限事項、および Apache ハイブで使用されるデータ モデルについて説明します。
また、Hive のデータ型、データ定義言語、データ操作言語についても説明します。最後のセクションでは、ビュー、パーティショニング、バケット化、結合、組み込み関数と演算子などの高度な Hive 概念について説明します。
このコースでは、面接でよく聞かれる質問と回答を取り上げます。これは、Apache Hive について、そしてそれを現実の世界でどのように応用できるかを学ぶのに最適なコースです。
#3. Apache Hive Basic をさらに進める

「Apache Hive Basic to Progress」は、Apache Hive やその他のビッグ データ ツールの使用経験が豊富なシニア データ エンジニアである Anshul Jain によるコースです。
これは、Apache Hive の概念をわかりやすい方法で示しており、Apache Hive のコツを学びたい初心者に適しています。
このコースでは、HQL 句、ウィンドウ関数、マテリアライズド ビュー、Hive での CRUD 操作、パーティションの交換、および高速なデータ クエリを可能にするパフォーマンスの最適化について説明します。
このコースでは、Apache Hive を実際に体験できるほか、求人応募時に遭遇する可能性が高い面接での一般的な質問に対処することもできます。
#4. Apache Hive の必需品
この本は、データ アナリスト、開発者、または Apache Hive の使用方法を学ぶことに興味がある人にとって特に役立ちます。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|

|
Apache Hive Essentials: 大きなデータを処理し、そこから独自の洞察を得るのに役立つ重要なテクニック。 | $32.99 | アマゾンで購入する |
著者は、ビッグデータの専門家として、さまざまな業界でエンタープライズ ビッグ データ アーキテクチャと分析を設計および実装してきた 10 年以上の経験があります。
この本では、Hive 環境を作成および設定する方法、Hive の定義言語を使用してデータを効果的に記述する方法、Hive でデータ セットを結合およびフィルターする方法について説明します。
さらに、Hive の並べ替え、順序付け、関数を使用したデータ変換、データの集計とサンプリングの方法、Hive クエリのパフォーマンスを向上させ、Hive のセキュリティを強化する方法についても説明します。最後に、Apache Hive のカスタマイズについて説明し、ビッグ データのニーズに応えるために Apache Hive を微調整する方法をユーザーに説明します。
#5. Apache Hive クックブック
Kindle とペーパーバックで入手可能な Apache Hive Cookbook は、Apache Hive についてのわかりやすく実践的な内容を提供しており、Apache Hive とビッグ データの一般的なフレームワークとの統合を学習して理解することができます。
| プレビュー | 製品 | 評価 | 価格 | |
|---|---|---|---|---|

|
Apache Hive クックブック | $48.99 | アマゾンで購入する |
この本は、SQL の予備知識がある読者を対象としており、Hadoop を使用した Apache Hive の構成方法、Hive のサービス、Hive データ モデル、および Hive データの定義と操作言語について説明しています。
さらに、Hive の拡張機能、結合と結合の最適化、Hive の統計、Hive 関数、最適化のための Hive チューニング、Hive のセキュリティについて説明し、最後に Hive と他のフレームワークの統合について詳しく説明します。
結論
Apache Hive は従来のデータ ウェアハウジング タスクに最適に使用され、オンライン トランザクションの処理には適していないことに注意してください。 Apache は、パフォーマンス、スケーラビリティ、耐障害性、および入力形式との疎結合を最大化するように設計されています。
大量のデータを処理および処理する組織は、Apache Hive が提供する堅牢な機能から多大なメリットを得ることができます。これらの機能は、大規模なデータセットの保存と分析に非常に役立ちます。
Apache Hive と Apache Impala の主な違いをいくつか調べることもできます。




")
![2021 年に Raspberry Pi Web サーバーをセットアップする方法 [ガイド]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)





