
データベースクエリを高速化したいですか? SQL を使用してデータベース インデックスを作成し、クエリのパフォーマンスを最適化し、データ取得を高速化する方法を学びます。
データベース テーブルからデータを取得する場合、特定の列に基づいてフィルタリングする必要がさらに多くなります。
特定の条件に基づいてデータを取得する SQL クエリを作成するとします。デフォルトでは、クエリを実行すると、条件を満たすすべてのレコードが見つかるまでテーブル 全体のスキャン が実行され、結果が返されます。
数百万行を含む大規模なデータベース テーブルに対してクエリを実行する必要がある場合、これは非常に非効率的になる可能性があります。 データベース インデックス を作成すると、このようなクエリを高速化できます。
![[解説] SQL でデータベース インデックスを作成する方法](https://it-biz.online/wp-content/uploads/2023/03/create_index-800x442.png)
データベースインデックスとは何ですか?
本の中で特定の用語を見つけたいとき、書籍全体を 1 ページずつスキャンして特定の用語を探しますか?そうですね、そうではありません。
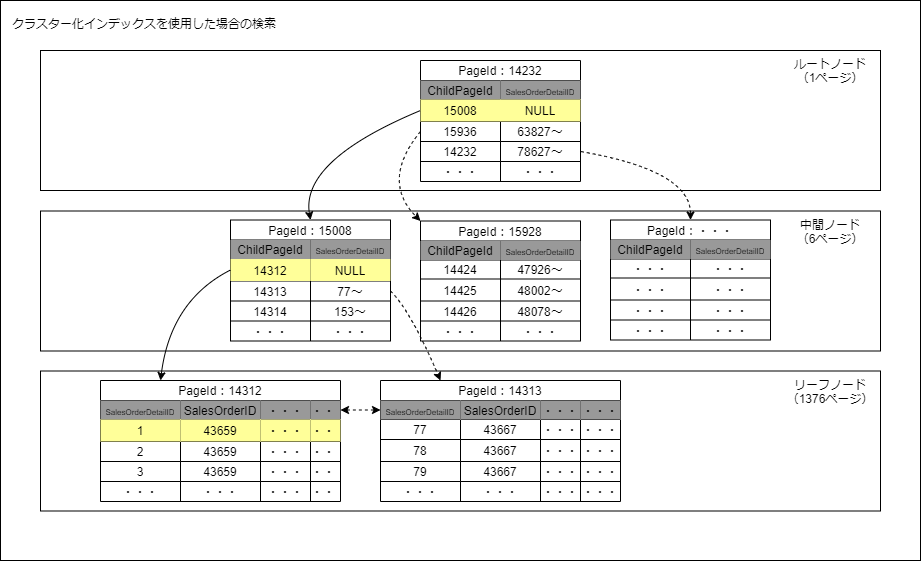
代わりに、 索引を参照して その 用語を参照しているページを見つけて、それらのページに直接ジャンプします。データベースのインデックスは、書籍のインデックスとよく似ています。
データベース インデックスは、実際のデータへのポインタまたは参照のセットですが、データの取得を高速化する方法で 並べ替えられています 。内部的には、B+ ツリーやハッシュ テーブルなどのデータ構造を使用してデータベース インデックスを実装できます。したがって、データベース インデックスにより、データ検索操作の速度と効率が向上します。
![[解説] SQL でデータベース インデックスを作成する方法](https://lh6.googleusercontent.com/AjTkSfs4cfG-NCVZSdbQwUoU8ahyP3zB085TyzcTUSgHinKodNNKyThtSE7-aWiQp2ItuRfqVDLM3em2ygfKi25K3B8kuVBCIbIQqickW79ZyUuFlPhbfh077gUOfuyf2JdSEB4i)
SQL でのデータベース インデックスの作成
データベース インデックスとは何か、そしてデータベース インデックスによってデータ検索がどのように高速化されるのかがわかったので、SQL でデータベース インデックスを作成する方法を学びましょう。
WHERE 句を使用して取得条件を指定してフィルタリング操作を実行する場合、特定の列を他の列よりも頻繁にクエリすることができます。
CREATE INDEX index_name ON table (column)
ここ、
-
index_nameは作成されるインデックスの名前です。 -
tableリレーショナル データベース内のテーブルを指します -
columnインデックスを作成する必要があるデータベース テーブル内の列の名前を指します。
要件に応じて、複数の列にインデックス (複数列インデックス) を作成することもできます。そのための構文は次のとおりです。
CREATE INDEX index_name ON table (column_1, column_2,...,column_k)
それでは実際の例に移りましょう。
![[解説] SQL でデータベース インデックスを作成する方法](https://tech.pjin.jp/wp-content/uploads/2021/09/1efad1b5aa917a846fa5b3fc11367269-2-1024x710.png)
データベースインデックスのパフォーマンス向上の理解
インデックスを作成する利点を理解するには、多数のレコードを含むデータベース テーブルを作成する必要があります。コード例は SQLite 用です。ただし、PostgreSQL や MySQL など、他の RDBMS を選択して使用することもできます。
データベーステーブルにレコードを設定する
Python の組み込みランダム モジュールを使用してレコードを作成し、データベースに挿入することもできます。ただし、 Faker を使用してデータベース テーブルに 100 万行を入力します。
次の Python スクリプト:
-
customer_dbデータベースを作成して接続します。 -
first_name、last_name、city、およびnum_ordersフィールドを含むcustomersテーブルを作成します。 -
合成データを生成し、データ (100 万件のレコード) を
customersテーブルに挿入します。
コードは GitHub に もあります。
# main.py
# imports
import sqlite3
from faker import Faker
import random
# connect to the db
db_conn = sqlite3.connect('customer_db.db')
db_cursor = db_conn.cursor()
# create table
db_cursor.execute('''CREATE TABLE customers (
id INTEGER PRIMARY KEY,
first_name TEXT,
last_name TEXT,
city TEXT,
num_orders INTEGER)''')
# create a Faker object
fake = Faker()
Faker.seed(27)
# create and insert 1 million records
num_records = 1_000_000
for _ in range(num_records):
first_name = fake.first_name()
last_name = fake.last_name()
city = fake.city()
num_orders = random.randint(0,100)
db_cursor.execute('INSERT INTO customers (first_name, last_name, city, num_orders) VALUES (?,?,?,?)', (first_name, last_name, city, num_orders))
# commit the transaction and close the cursor and connection
db_conn.commit()
db_cursor.close()
db_conn.close()
これでクエリを開始できるようになりました。
都市列のインデックスの作成
city
列に基づいてフィルタリングして顧客情報を取得するとします。 SELECT クエリは次のようになります。
SELECT column(s) FROM customers
WHERE condition;
そこで、
customers
テーブルの
city
列に
city_idx
を作成しましょう。
CREATE INDEX city_idx ON customers (city);
⚠ インデックスの作成には無視できない時間がかかり、1 回限りの操作です。ただし、
city列でフィルタリングすることにより、多数のクエリが必要な場合のパフォーマンス上の利点は大きくなります。
データベースインデックスの削除
インデックスを削除するには、次のように
DROP INDEX
ステートメントを使用します。
DROP INDEX index_name;
インデックスありとインデックスなしのクエリ時間の比較
Python スクリプト内でクエリを実行する場合は、デフォルトのタイマーを使用してクエリの実行時間を取得できます。
あるいは、sqlite3 コマンドライン クライアントを使用してクエリを実行することもできます。コマンドライン クライアントを使用して
customer_db.db
を操作するには、ターミナルで次のコマンドを実行します。
$ sqlite3 customer_db.db;
おおよその実行時間を取得するには、sqlite3 に組み込まれている
.timer
機能を次のように使用できます。
sqlite3 > .timer on
> <query here>
city
列にインデックスを作成したため、
WHERE
句の
city
列に基づくフィルタリングを含むクエリが大幅に高速になります。
まず、クエリを実行します。次に、インデックスを作成し、クエリを再実行します。両方の場合の実行時間を書き留めます。ここではいくつかの例を示します。
| クエリ | インデックスなしの時間 | インデックス付きの時間 |
|---|---|---|
|
顧客から * を選択
「New%」のような都市はどこですか リミット10; |
0.100秒 | 0.001秒 |
|
顧客から * を選択
WHERE city=’ニュー・ウェスリー’; |
0.148秒 | 0.001秒 |
|
顧客から * を選択
WHERE city IN (「New Wesley」、「New Steven」、「New Carmenmouth」); |
0.247秒 | 0.003秒 |
インデックスを使用した場合の取得時間は、city 列のインデックスを使用しない場合よりも数桁高速であることがわかります。
データベースインデックスを作成および使用するためのベストプラクティス
パフォーマンスの向上がデータベース インデックスの作成のオーバーヘッドよりも大きいかどうかを常に確認する必要があります。以下に留意すべきベスト プラクティスをいくつか示します。
- 適切な列を選択してインデックスを作成します。オーバーヘッドが大きくなるため、インデックスを作成しすぎることは避けてください。
- インデックス付きの列が更新されるたびに、対応するインデックスも更新される必要があります。したがって、データベース インデックスを作成すると (検索は高速化されますが)、挿入と更新の操作が大幅に 遅くなります 。したがって、クエリは頻繁に行われるが更新されることはほとんどない列にインデックスを作成する必要があります。
インデックスを作成すべきではないのはどのような場合ですか?
ここまでで、いつどのようにインデックスを作成するかについて理解できたはずです。ただし、データベース インデックスが必要でない場合についても述べてみましょう。
- データベース テーブルが小さく、多数の行が含まれていない場合、データを取得するための全テーブル スキャンのコストはそれほど高くありません。
- 検索にほとんど使用されない列にはインデックスを作成しないでください。頻繁にクエリが実行されない列にインデックスを作成すると、インデックスの作成と維持にかかるコストがパフォーマンスの向上を上回ります。
まとめ
学んだことを復習してみましょう。
- データを取得するためにデータベースにクエリを実行する場合、特定の列に基づいてより頻繁にフィルタリングする必要がある場合があります。このような頻繁にクエリされる列にデータベース インデックスを付けると、パフォーマンスが向上します。
-
単一の列にインデックスを作成するには、
CREATE INDEX index_name ON table (column)という構文を使用します。複数列のインデックスを作成する場合は、CREATE INDEX index_name ON table (column_1, column_2,...,column_k)使用します。 - インデックス付きの列が変更されるたびに、対応するインデックスも更新する必要があります。したがって、インデックスを作成するには、頻繁にクエリが行われ、更新頻度はそれほど高くない適切な列を選択してください。
- データベース テーブルが比較的小さい場合、インデックスの作成、維持、更新にかかるコストがパフォーマンスの向上よりも高くなります。
最新のデータベース管理システムには、特定の列のインデックスによってクエリの実行が高速化されるかどうかを確認するクエリ オプティマイザーが備わっています。次に、データベース設計のベスト プラクティスを学びましょう。




")
![2021 年に Raspberry Pi Web サーバーをセットアップする方法 [ガイド]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)





