
すべての AWS サービスは、その処理を CloudWatch ログ グループの下に整理されたファイルに記録します。通常、ログ グループには、識別しやすいようにサービス自体の名前が付けられます。サービスのシステム メッセージまたは一般的な状態情報は、デフォルトでこれらのログ ファイルに書き込まれます。
ただし、デフォルトのログ メッセージ情報に加えてカスタム ログ メッセージ情報を追加できます。このようなログが賢明に作成されれば、有用な CloudWatch ダッシュボードの作成に役立ちます。
ジョブ処理に関する追加の詳細を提供するメトリクスと構造化情報を使用します。サービスに関するシステムのような情報を含む標準ウィジェットを含めることができるだけではありません。これを独自のコンテンツで拡張し、カスタム ウィジェットまたは指標に集約できます。
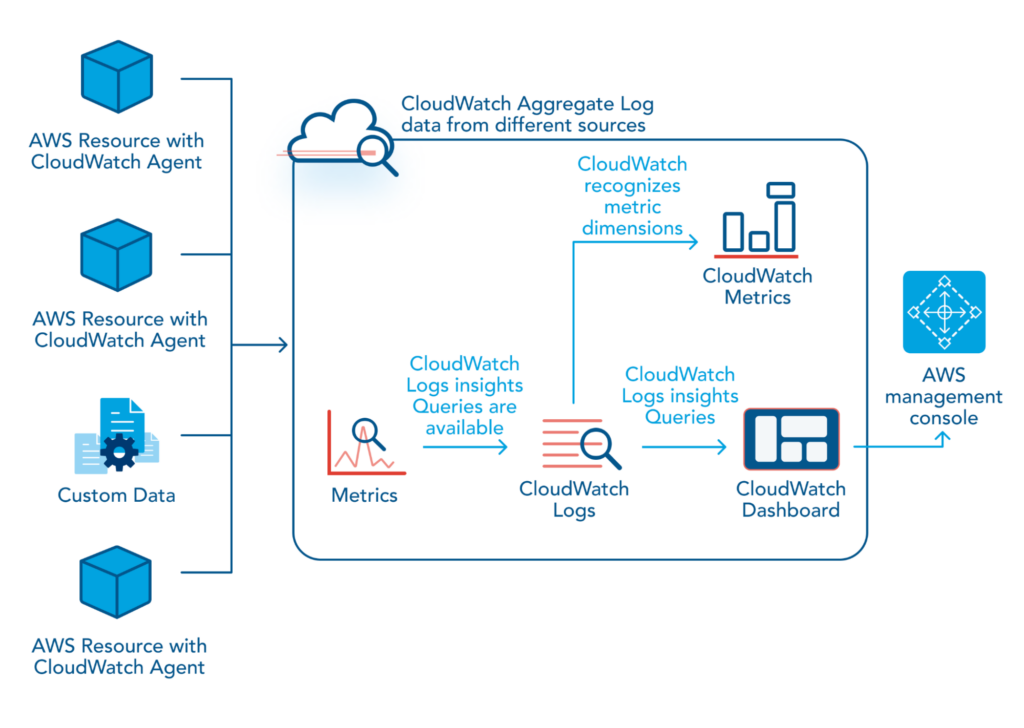
ログファイルのクエリ

AWS CloudWatch Log Insights を使用すると、AWS リソースからのログデータをリアルタイムで検索して分析できます。データベースビューとして見ることができます。ダッシュボードでクエリを定義すると、ダッシュボード ビュー内で定義したときに、ダッシュボードにアクセスしたとき、または過去の指定された時間枠でそのクエリが選択されます。
CloudWatch Logs Insights と呼ばれるクエリ言語を使用して、ログ データを検索および分析します。クエリ言語は SQL 言語のサブセットに基づいています。ログ データを検索およびフィルタリングできます。特定のログ イベント、カスタム ログ テキストまたはキーワードを検索し、特定のフィールドに基づいてログ データをフィルタリングできます。そして最も重要なことは、1 つ以上のログ ファイル内のログ データを集約して、要約されたメトリクスと視覚化を生成することです。
クエリを実行すると、CloudWatch Log Insights はロググループ内のログデータを検索します。次に、クエリ基準に一致するファイルから得られたテキストを返します。
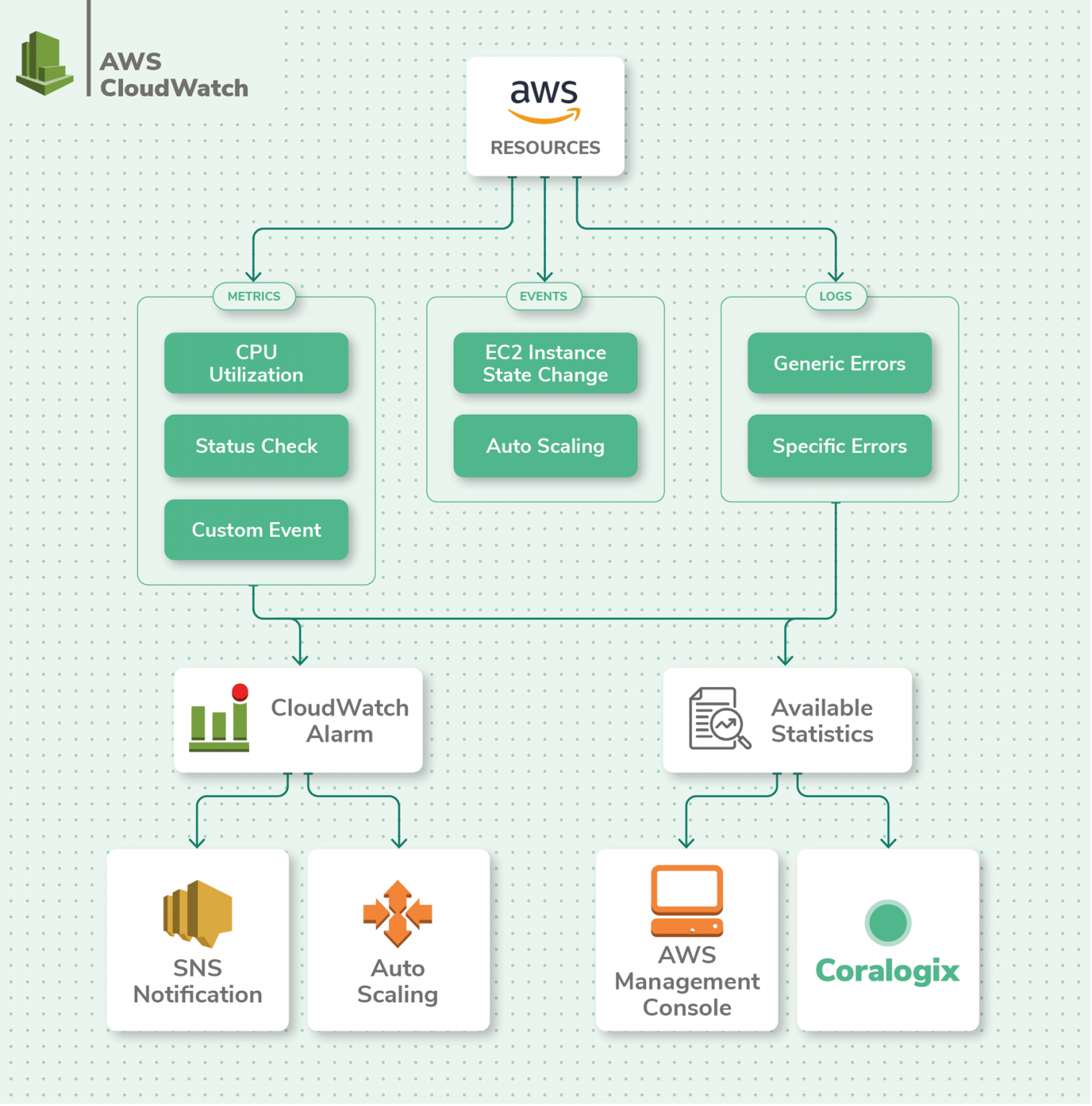
ログファイルクエリの例
概念を理解するために、いくつかの基本的なクエリを見てみましょう。
デフォルトでは、すべてのサービスがいくつかの重大なサービス エラーをログに記録します。このようなエラー イベント専用のカスタム ログを作成しなくても。次に、簡単なクエリを使用して、過去 1 時間のアプリケーション ログ内のエラーの数をカウントできます。
fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
または、過去 1 日の API の平均応答時間を監視する方法は次のとおりです。
fields @timestamp, @message
| filter @message like /API response time/
| stats avg(response_time) by bin(1d)
デフォルトでは、CPU 使用率はサービスによって CloudWatch に記録される情報であるため、このタイプのメトリクスも収集できます。
fields @timestamp, @message
| filter @message like /CPUUtilization/
| stats avg(value) by bin(1h)
これらのクエリは、特定のユースケースに合わせてカスタマイズでき、CloudWatch ダッシュボードでカスタムメトリクスと視覚化を作成するために使用できます。その方法は、ダッシュボードにウィジェットを配置し、ウィジェット内にコードを配置して何を選択するかを定義することです。
CloudWatch ダッシュボードで使用でき、Log Insights のコンテンツを入力できるウィジェットの一部を次に示します。
- テキスト ウィジェット – CloudWatch Insights クエリの出力などのテキストベースの情報を表示します。
- ログクエリウィジェット – アプリケーションログのエラー数など、CloudWatch Insights ログクエリの結果を表示します。
ダッシュボードに役立つログ情報を作成する方法
CloudWatch ダッシュボードで CloudWatch Insights クエリを効果的に使用するには、システムで使用するサービスごとに CloudWatch ログを作成するときにいくつかのベスト プラクティスに従うことをお勧めします。以下にいくつかのヒントを示します。
#1. 構造化ログを使用する
事前定義されたスキーマを使用してデータを構造化形式でログに記録するログ形式を使用する必要があります。これにより、CloudWatch Insights クエリを使用したログデータの検索とフィルタリングが容易になります。
これは基本的に、アーキテクチャ プラットフォーム内のさまざまなサービスにわたってログを標準化することを意味します。開発標準で定義することは非常に役立ちます。
たとえば、特定のデータベース テーブルに関連する各問題が、「[TABLE_NAME] 警告 / エラー: <メッセージ>」のような開始メッセージとともにログに記録されるように定義できます。
または、「[FULL/DELTA]」などのプレフィックスを使用してフル データ ジョブとデルタ データ ジョブを分離し、具体的なデータ プロセスに関連するメッセージのみを選択することもできます。
特定のソース システムからのデータを処理するときに、システムの名前が関連する各ログ エントリのプレフィックスになるように定義できます。後でそのようなメッセージをログ ファイルからフィルタリングして、それらのメッセージに基づいてメトリクスを構築する方がはるかに簡単です。
#2. 一貫したログ形式を使用する
すべての AWS リソースにわたって一貫したログ形式を使用すると、CloudWatch Insights クエリを使用したログ データの検索とフィルタリングが容易になります。
先ほどの点とも関係しますが、実はログのフォーマットが標準化されていればいるほど、ログデータは使いやすくなります。開発者はその形式を信頼して、直感的にも使用できるようになります。
残酷な事実は、ほとんどのプロジェクトがログに関する標準を気にしていないことです。さらに、多くのプロジェクトはカスタム ログをまったく作成しません。それは衝撃的ですが、同時に非常に一般的でもあります。
エラー処理アプローチなしでどうやって人々がここで生活できるのだろうと何度思ったかわかりません。そして、誰かが例外として何らかのエラー処理をしようとしたとしたら、それは間違ったことです。
したがって、一貫したログ形式は強力な資産となります。持っている人は多くありません。
#3. 関連するメタデータを含める
タイムスタンプ、リソース ID、エラー コードなどのメタデータをログ データに含めると、CloudWatch Insights クエリを使用したログ データの検索とフィルタリングが容易になります。
#4. ログローテーションを有効にする
ログ ローテーションを有効にすると、ログ データが大きくなりすぎるのを防ぎ、CloudWatch Insights クエリを使用したログ データの検索とフィルタリングが容易になります。
ログ データがないことも問題ですが、構造化されていないログ データが多すぎることも同様に絶望的です。データを使用できない場合は、データがまったくないのと同じです。
#5. CloudWatch Logs エージェントを使用する
自分ではどうすることもできず、カスタマイズされたログ システムの構築を拒否する場合は、少なくとも CloudWatch Logs エージェントを使用してください。ログ データは AWS リソースから CloudWatch Logs に自動的に送信されます。これにより、CloudWatch Insights クエリを使用したログデータの検索とフィルタリングが容易になります。
より複雑なインサイトクエリの例
CloudWatch Insights のクエリは、わずか 2 行のステートメントよりも複雑になる場合があります。
fields @timestamp, @message
| filter @message like /ERROR/
| filter @message not like /404/
| parse @message /.*\[(?<timestamp>[^\]]+)\].*\"(?<method>[^\s]+)\s+(?<path>[^\s]+).*\" (?<status>\d+) (?<response_time>\d+)/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| sort count desc
| limit 20
このクエリは次のことを行います。
- 文字列「ERROR」を含むが「404」を含まないログ イベントを選択します。
- ログ メッセージを解析して、タイムスタンプ、HTTP メソッド、パス、ステータス コード、および応答時間を抽出します。
- HTTP メソッド、パス、ステータス コード、時間の組み合わせごとに、平均応答時間とログ イベント数を計算します。
- 結果を降順にカウントして並べ替えます。
- 出力を上位 20 件の結果に制限します。
このクエリは、アプリケーションで最も一般的なエラーを特定し、HTTP メソッド、パス、ステータス コードの組み合わせごとの平均応答時間を追跡します。結果を使用して CloudWatch ダッシュボードでカスタムメトリクスと視覚化を作成し、Web アプリケーションのパフォーマンスを監視し、問題のトラブルシューティングを行うことができます。
Amazon S3 サービス メッセージをクエリする別の例:
fields @timestamp, @message
| filter @message like /REST\.API\.REQUEST/
| parse @message /.*\"(?<method>[^\s]+)\s+(?<path>[^\s]+).*\" (?<status>\d+) (?<response_time>\d+)/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| sort count desc
| limit 20
- このクエリは、文字列「REST.API.REQUEST」を含むログ イベントを選択します。
- 次に、ログ メッセージを解析して、HTTP メソッド、パス、ステータス コード、および応答時間を抽出します。
- HTTP メソッド、パス、ステータス コードの組み合わせごとに平均応答時間とログ イベントの数を計算し、結果をカウントの降順に並べ替えます。
- 出力を上位 20 件の結果に制限します。
このクエリの出力を使用して、HTTP メソッド、パス、ステータス コードの組み合わせごとの平均応答時間を経時的に示す折れ線グラフを CloudWatch ダッシュボードに作成できます。
ダッシュボードの構築
CloudWatch Insights ログクエリの出力から CloudWatch ダッシュボードにメトリクスと視覚化を入力するには、CloudWatch コンソールに移動し、ダッシュボード ウィザードに従ってコンテンツを構築します。
その後、CloudWatch ダッシュボードのコードは次のようになり、CloudWatch Insights クエリ データによって埋められるメトリクスが含まれます。
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
この CloudWatch ダッシュボードには 2 つのウィジェットが含まれています。
- EC2 インスタンスの平均 CPU 使用率を経時的に表示するメトリック ウィジェット。 CloudWatch Insights クエリによりウィジェットが設定されます。特定の EC2 インスタンスの CPU 使用率データを選択し、5 分間隔で集計します。
- アプリケーション エラーの数を経時的に表示するログ ウィジェット。 「ERROR」という文字列を含むログイベントを選択し、時間ごとに集計します。
これは、ダッシュボードとメトリクスの定義が含まれる JSON 形式のファイルです。これには、インサイト クエリ自体も (プロパティとして) 含まれます。
コードを取得して、必要な AWS アカウントにデプロイできます。サービスとログ メッセージがすべての AWS アカウントとステージで一貫していると仮定すると、ダッシュボードは、ダッシュボードのソース コードを変更することなく、すべてのアカウントで機能します。
最後の言葉
強固なロギング構造を構築することは、常にシステムの信頼性の将来への良い投資でした。今ではさらに大きな目的を果たすことができます。その副作用として、メトリクスとビジュアライゼーションを備えた便利なダッシュボードを作成できます。
必要な作業は一度だけ行う必要があり、少しの追加作業だけで済むため、開発チーム、テスト チーム、実稼働ユーザーはすべて同じソリューションの恩恵を受けることができます。
次に、最高の AWS 監視ツールをチェックしてください。




")
![2021 年に Raspberry Pi Web サーバーをセットアップする方法 [ガイド]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)





