Data is a critical asset that can improve operations, efficiency, customer experience, and decision-making.
Toward this end, businesses and organizations generate, collect, and store large amounts of data from a variety of sources. However, as the amount of data increases, it can become difficult to extract the most useful information, especially when the information is unorganized and spread out in different locations.
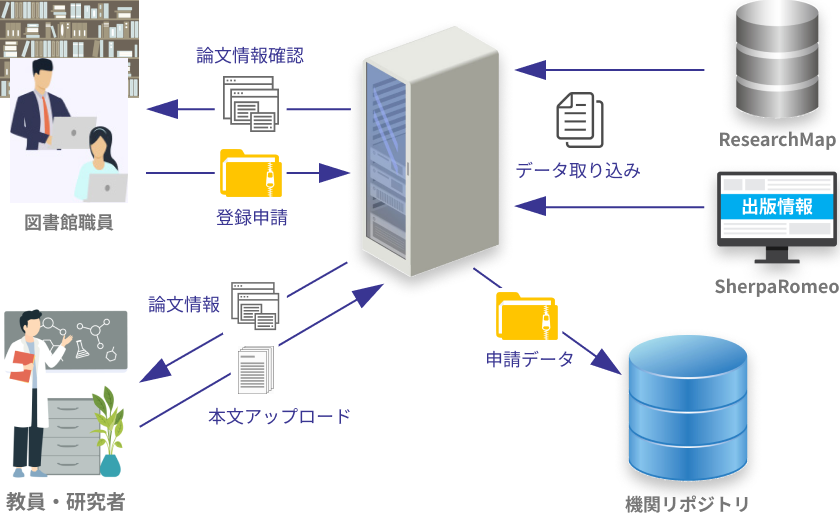
One way to overcome these challenges is to store data in appropriate data repositories. This provides a unified data source with information that is filtered, searchable, and ready for analysis and reporting.
Define data repositories and learn about their benefits, different types, and best practices.
What is a data repository?
A data repository is a library or archive that contains data that supports analytical and reporting functions in research or business operations. In reality, a data repository is a general term that refers to a central location where data is stored. This can refer to a single storage device, or it can refer to a set of databases across different devices.
In typical operations, organizations may collect disparate data from POS, CRM, ERP, spreadsheets, and other sources. It is then moved to a data repository where it is sorted, cleaned, validated, formatted, organized, and stored.
Organizations typically separate and store certain types of data in repositories for analysis and reporting purposes. It is also long-term stored and can be reused many times to perform different types of analyses.
A typical data repository has three main tiers.
- data source layer
- Data processing layer or warehouse
- Target application tier consisting of users, analysts, reports, etc.
Why do I need a data repository?
Data is available from customer touchpoints, the internet, research, marketing, applications, and many other sources. However, it is usually in raw form and organizations need the right tools to extract useful information that will help them achieve their objectives. We recommend creating a data repository to organize your data and make it available for analysis and other applications.
Repositories allow authorized users to easily and quickly access, retrieve, and manage data using search, query, and other tools. As a result, users and businesses can analyze, investigate, share, and report. This allows you to streamline operations and make better decisions based on data.
Let’s say you want to see which departments in your organization have the most operational costs. Create a data repository for leases, security, energy costs, utilities, and other expenses. Having your data in a central location allows you to analyze and identify departments where the most spending is occurring, making more informed and focused decisions when you want to reduce costs. You can.
Data repositories are often used in research and scientific institutions, but they can also be applied to general organizations and businesses.
Advantages of data repositories
Most organizations today use data repositories as a way to manage and utilize data more efficiently. The concept of data repositories continues to grow in popularity due to benefits such as easy access to information, management, analysis, and reporting.
Other benefits include:
- Improved visibility : Store your data in a central, trusted location so it’s always accessible. In contrast, storing data in non-shared applications or local silos means that the data is only available to an individual or a small number of people. This reduces visibility and usability. As a result, it may take your team longer to access the data and additional resources may be used.
- Easy access to useful data: Data in digital format is easy to search and access. Adding metadata to data in your repository allows users to better understand and use the data.
- Easier to protect data and adhere to standards : It is much easier to protect data centrally, as opposed to having it spread out in many different locations. Additionally, data repositories make it easier and cheaper to comply with various regulatory standards.
- Reusable data: Data repositories contain a variety of data for analysis and reporting. Analysts and researchers can use the same data to generate different types of reports.
- Provide useful insights: With the right tools in your data repository, you can get a multidimensional view of your data rather than analyzing information in different places.
Types of data repositories
Data repository is a general term that refers to an information archive. However, there are different repositories depending on the target application and purpose. The four main types of data repositories are listed below.
#1. data warehouse
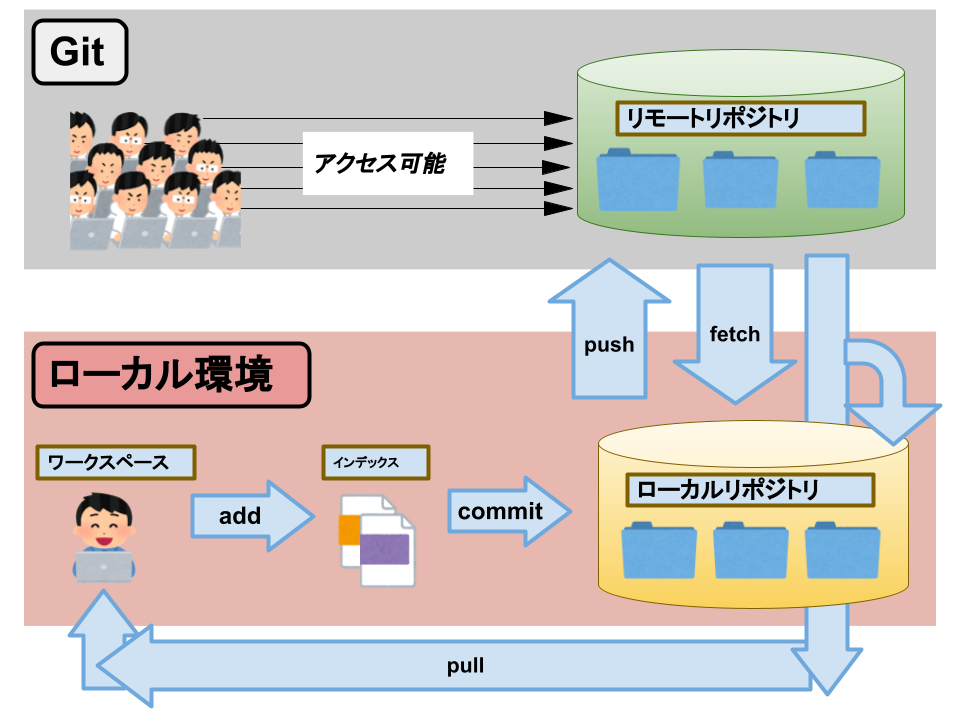
Data warehouses are one of the largest data repository types. In this category, companies may collect data from multiple sources and in different formats. A typical data warehouse stores large amounts of data from various sources. Its structure allows organizations to easily organize, analyze, and report on data. This allows teams to make better decisions based on data.
Information in a data warehouse may cover multiple subjects and is typically cleaned, filtered, and defined for specific uses.
#2. data market
A data mart is an isolated section of a data warehouse. Subject-oriented data repositories store subsets of data that focus on specific business functions or departments, such as finance, support, purchasing, or marketing.
Data marts are typically small in size. This speeds up business processes by providing faster access to relevant data. These provide a cost-effective means to quickly gain actionable insights.
#3. data lake
A data lake is a large archive containing data in all formats. This includes unstructured data, semi-structured data, and structured data. Metadata is used to categorize and label data, but the data is largely unstructured. Data lakes provide more complete control and better data governance than data warehouses.
#4. data cube
Data cubes are multidimensional data repositories that focus on complex data not supported by other types. These have three or more dimensions, each representing a specific characteristic such as daily, monthly, or annual costs or revenue. Data lakes allow researchers to evaluate data from various perspectives.
Also read: Data Lake vs. Data Warehouse: What’s the Difference?
Best practices for designing and maintaining data repositories
A typical data repository provides tools to store, manage, and protect information. Features include access control, indexing, compression, reporting, and encryption.
In addition to working with data pipeline engineers, data analysts, and other experts, you should consider several hardware and software elements when designing and creating a data repository. Depending on your domain, you may need to involve industry experts. For example, if you create a clinical data repository, you’ll be collaborating with physicians and other medical professionals.
An effective data management strategy includes:
✅ Organize your files
✅ Secure storage and proper access control
✅ Version and document management
✅ Supports collaboration
✅ Clear policies regarding reuse and sharing
✅ Archive and store data for future reference or use.
The steps for designing, creating, and managing a data repository may vary by industry and organization, but below are some best practices.
Limit scope early on
Initially, it is a best practice to use a smaller range of data repositories. One strategy is to reduce the number of target areas and datasets used and gradually increase the scope.
Choose the right tool
Tools are essential for creating, storing, sharing, analyzing, and managing data repositories. Therefore, data quality and analysis depend on the tools used. There are different types of tools with different features, so make sure the one you choose meets your needs.
Automate as many processes as possible
Where possible, automate loading and maintenance tasks to improve efficiency and reduce wasted time and risk of errors.
Design a flexible and scalable repository
To accommodate increasing data volumes and evolving data types and formats, it is a best practice to design and create a scalable repository. Such systems will be able to meet current needs and support increasing types and amounts of data in the future. You must also be able to flexibly work with a variety of tools and new technologies.
Always protect your data
Ensure data integrity and security, as discrepancies, compromises, and theft can lead to inaccurate analysis results and wrong decisions. Set appropriate access rules to give authorized users only the privileges they need to perform their jobs. Additionally, we encrypt your data at rest and in transit. Consider other measures such as multi-factor authentication to add an additional layer of protection.
Use standard data model
Data modeling helps turn data into valuable information that researchers and business leaders can better understand. Information in a data repository is typically reusable.
Organizations can use the same data to extract useful information in different areas. Data has different contexts based on how it is used in different processes and analytical applications. As a result, organizations may use multiple data models to serve different analytical needs.
Indexing data
Creating indexes on data repository tables improves query performance and should be done as standard practice. Speeds up queries by providing organized lookup tables with entries that point to specific data locations based on specific attributes.
Data repository indexing may vary depending on your usage. Depending on the application, it can be lightweight or wide-ranging. Ideally, your indexing strategy should focus on speeding up the ETL process. One of the best practices when converting data is to ensure that the indexes provide the information you need without missing useful data or becoming unnecessarily large.
It is also important to balance the trade-off between improving data repository query performance and the overhead and maintenance costs associated with indexing.
Also read: Best ETL tools for SMBs to use.
Data repository example
Data repositories are divided into different categories:
- Institutional repositories (IRs) for researchers’ institutions, such as the Texas Data Repository by Texas A&M University Libraries.
- Discipline or domain-specific repositories (DR): These These are domain-specific and operated by consortia of researchers or professional organizations, such as DataCite’s Registry of Research Data Repositories (re3data) or the Directory of Open Access Repositories (OpenDOAR), which is comprised of multiple academic open access repositories. .
- Open or general-purpose repositories such as Dryad , Figshare , and Harvard Dataverse .
Examples of using data repositories
Fintech, healthcare, e-commerce, supply chain, and other industries can benefit from using data repositories. By making full use of the large amounts of data we collect and generate, we can gain better insights to optimize our services and provide better and faster service.
clinical research

Clinical research is a data-intensive field. Making the most of data can help steer the healthcare industry in the right direction. Analyzing big data allows scientists and other experts to dig deeper into clinical trials and gain insights that can improve healthcare and save lives.
Financial operations
The financial services industry can benefit from analyzing the large amounts of data it holds. This analysis provides insights that can be used to improve service, efficiency, and revenue. Areas where financial institutions can use data repositories include:
- To analyze data and create financial reports from a central location.
- Enable automated decision-making using AI.
last word
Data is an essential asset in decision-making. However, organizations that store large amounts of data need appropriate solutions to collect, store, manage, and analyze that data.
Toward this end, data repositories provide solutions to integrate and manage critical data. Repositories allow organizations to analyze data, gain insights, and make better decisions based on the data.
A data repository stores different types of information in a logical central location, making it easy to access, search, analyze, and manage. It also helps organizations protect, share, maintain, and ensure the integrity and quality of data and comply with regulatory standards.
Next, check out the best data management tools for medium to large businesses.




![How to set up a Raspberry Pi web server in 2021 [Guide]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)

")






 in Roblox")
")




")


















")









")
