Confusion matrices are tools to evaluate the performance of classification types of supervised machine learning algorithms.
What is a confusion matrix?
We humans perceive things differently, even truth and lies. A 10cm long line to me may look like a 9cm long line to you. However, the actual value may be 9, 10, or some other value. What we estimate is the predicted value.
Just like our brains apply their own logic to predict something, machines also apply different algorithms (called machine learning algorithms) to arrive at a predicted value for a question. . Again, these values may or may not be the same as your actual values.
In a competitive world, people want to know whether their predictions are correct to understand their performance. Similarly, the performance of a machine learning algorithm can be judged by the number of correct predictions it makes.
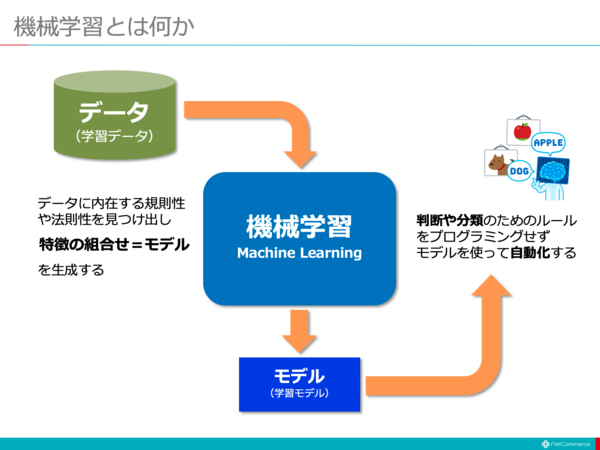
So what are machine learning algorithms?
A machine attempts to arrive at a specific answer to a problem by applying a specific logic or set of instructions called a machine learning algorithm. There are three types of machine learning algorithms: supervised, unsupervised, and reinforcement.
The simplest type of algorithm is supervised, and if we already know the answer, we train the machine to arrive at that answer by training the algorithm with large amounts of data. This is the same way children distinguish between people of different age groups. I look at their features over and over again.
There are two types of supervised ML algorithms: classification and regression.
Classification algorithms classify or sort data based on a set of criteria. For example, if you need an algorithm to group customers based on food preferences, such as people who like pizza and people who don’t like pizza, use classification algorithms such as decision trees, random forests, Naive Bayes, or SVM. (support vector machine).
Which of these algorithms will give you the best results? Why should you choose one algorithm over another?
Please enter the confusion matrix….
A confusion matrix is a matrix or table that provides information about the accuracy of a classification algorithm in classifying a dataset. Well, not a name meant to confuse humans, but too many incorrect predictions probably means the algorithm got confused 😉!
Therefore, a confusion matrix is a way to evaluate the performance of a classification algorithm.
how?
Suppose we apply different algorithms to the binary problem mentioned above. That is, classifying (separating) people based on whether they like pizza or not. Use a confusion matrix to evaluate the algorithm with the values closest to the correct answer. For binary classification problems (like/dislike, true/false, 1/0), the confusion matrix gives the following four grid values:
- true positive (TP)
- True negative (TN)
- False positive (FP)
- False negative (FN)
What are the four grids of the confusion matrix?
The four values determined using the confusion matrix form the grid of the matrix.
True positives (TP) and true negatives (TN) are the values correctly predicted by the classification algorithm.
- TP represents people who like pizza, and the model classified them correctly.
- TN represents people who don’t like pizza, and the model classified them correctly.
False positives (FP) and false negatives (FN) are values incorrectly predicted by the classifier.
- FP represents someone who doesn’t like pizza (negative), but the classifier predicted that they like pizza (falsely positive). FP is also known as Type I error.
- FN represents someone who likes pizza (positive), but the classifier predicted that they don’t like pizza (falsely negative). FN is also known as Type II error.
To understand this concept further, let’s consider a real-world scenario.
Let’s say you have a dataset of 400 people who have taken a Covid test. Now we have the results of the various algorithms that determine the number of Covid positive and negative cases.
Here are two confusion matrices for comparison.
 |  |
Looking at both, you might be tempted to say that the first algorithm is more accurate. However, to get concrete results, we need some metrics that can measure accuracy, precision, and many other values that prove which algorithm is better.
Metrics using confusion matrices and their importance
The main metrics that help determine whether the classifier made the correct predictions are:
#1.Recall /Sensitivity
Recall, sensitivity, true positive rate (TPR), or detection probability is the ratio of correct positive predictions (TP) to total positives (i.e., TP and FN).
R = TP/(TP + FN)
Recall is a measure of the number of correct positive results returned out of the number of possible correct positive results generated. The higher the value of Recall, the fewer false negatives, which is better for the algorithm. Use Recall when knowing about false negatives is important. For example, if a person has multiple blockages in their heart and the model shows that person is perfectly fine, it could turn out to be fatal.
#2.Accuracy
Accuracy is a measure of the correct positive result out of all predicted positive results, including both true positives and false positives.
Pr = TP/(TP + FP)
Accuracy is very important when false positives are too important to ignore. For example, suppose a person does not have diabetes, but the model shows that they do, and a doctor prescribes a certain medication. This can cause serious side effects.
#3.Specificity
Specificity or true negative rate (TNR) is the correct negative result found among all possible negative results.
S = TN/(TN + FP)
This is a measure of how well the classifier identifies negative values.
#4.Accuracy
Accuracy is the number of correct predictions out of the total number of predictions. Therefore, if you correctly find 20 positive values and 10 negative values out of 50 samples, your model will have an accuracy of 30/50.
Accuracy A = (TP + TN)/(TP + TN + FP + FN)
#5.Prevalence
Prevalence is a measure of the number of positive results obtained out of all results.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F score
Sometimes it is difficult to compare two classifiers (models) using only precision and recall, which are simply the arithmetic mean of the four grid combinations. In these cases, you can use the harmonic mean, the F-score or F1-score. This is more accurate because it doesn’t change much for very high values. A higher F-score (up to 1) indicates a better model.
F-score = 2*Precision*Recall/ (Recall + Precision)
F1 score is a good metric when it is important to deal with both false positives and negatives. For example, there is no need to unnecessarily isolate people who are not coronavirus positive (although the algorithm indicates so). Similarly, people who test positive for coronavirus (but the algorithm says otherwise) also need to isolate.
#7. ROC curve
Parameters like “accuracy” and “accuracy” are good metrics when the data is balanced. For unbalanced datasets, high accuracy does not necessarily mean that the classifier is efficient. For example, 90 out of 100 students in a group know Spanish. Now, even if the algorithm determined that all 100 people knew Spanish, its accuracy would be 90%, which could give a false picture about the model. When datasets are unbalanced, metrics such as ROC become more effective determinants.
The ROC (Receiver Operating Characteristic) curve visually displays the performance of a binary classification model at different classification thresholds. This is a plot of TPR (true positive rate) versus FPR (false positive rate), calculated as (1 – specificity) at various thresholds. The value closest to 45 degrees (top left) in the plot is the most accurate threshold. If the threshold is too high, there will be fewer false positives, but more false negatives, and vice versa.
Generally, when the ROC curves of different models are plotted, the model with the highest area under the curve (AUC) is considered the better model.
Let’s compute all the metric values of the confusion matrix for classifier I and classifier II.
It can be seen that the accuracy is higher for classifier II and slightly higher for classifier I. Based on the problem at hand, the decision maker can choose classifier I or II.
N x N confusion matrix
So far, we have looked at confusion matrices for binary classifiers. What if there were more categories than just “yes/no” or “like/dislike”? For example, if an algorithm sorts red, green, and blue images. This type of classification is called multiclass classification. The number of output variables also determines the size of the matrix. So in this case the confusion matrix will be 3×3.
summary
Confusion matrices are good evaluation systems because they provide detailed information about the performance of classification algorithms. This works well for binary classifiers as well as multiclass classifiers when there are more than two parameters to process. Confusion matrices are easy to visualize and can be used to generate all other metrics of performance such as F-score, precision, ROC, precision, etc.
We also discuss how to choose ML algorithms for regression problems.




![How to set up a Raspberry Pi web server in 2021 [Guide]](https://i0.wp.com/pcmanabu.com/wp-content/uploads/2019/10/web-server-02-309x198.png?w=1200&resize=1200,0&ssl=1)

")






 in Roblox")
")




")


















")









")
